Карты nvidia cuda. Что такое NVIDIA CUDA? А в это время…
Позвольте обратиться к истории - вернуться в 2003 год, когда Intel и AMD участвовали в совместной гонке за самый мощный процессор. Всего за несколько лет в результате этой гонки тактовые частоты существенно выросли, особенно после выхода Intel Pentium 4.
Но гонка быстро приближалась к пределу. После волны огромного прироста тактовых частот (между 2001 и 2003 годами тактовая частота Pentium 4 удвоилась с 1,5 до 3 ГГц), пользователям пришлось довольствоваться десятыми долями гигагерц, которые смогли выжать производители (с 2003 до 2005 тактовые частоты увеличились всего с 3 до 3,8 ГГц).
Даже архитектуры, оптимизированные под высокие тактовые частоты, та же Prescott, стали испытывать трудности, причём на этот раз не только производственные. Производители чипов просто упёрлись в законы физики. Некоторые аналитики даже предрекали, что закон Мура перестанет действовать. Но этого не произошло. Оригинальный смысл закона часто искажают, однако он касается числа транзисторов на поверхности кремниевого ядра. Долгое время повышение числа транзисторов в CPU сопровождалось соответствующим ростом производительности - что и привело к искажению смысла. Но затем ситуация усложнилась. Разработчики архитектуры CPU подошли к закону сокращения прироста: число транзисторов, которое требовалось добавить для нужного увеличения производительности, становилось всё большим, заводя в тупик.
 |
Пока производители CPU рвали на голове последние волосы, пытаясь найти решение своих проблем, производители GPU продолжали замечательно выигрывать от преимуществ закона Мура.

Почему же они не зашли в тот же тупик, как разработчики архитектуры CPU? Причина очень простая: центральные процессоры разрабатываются для получения максимальной производительности на потоке инструкций, которые обрабатывают разные данные (как целые числа, так и числа с плавающей запятой), производят случайный доступ к памяти и т.д. До сих пор разработчики пытаются обеспечить больший параллелизм инструкций - то есть выполнять как можно большее число инструкций параллельно. Так, например, с Pentium появилось суперскалярное выполнение, когда при некоторых условиях можно было выполнять две инструкции за такт. Pentium Pro получил внеочередное выполнение инструкций, позволившее оптимизировать работу вычислительных блоков. Проблема заключается в том, что у параллельного выполнения последовательного потока инструкций есть очевидные ограничения, поэтому слепое повышение числа вычислительных блоков не даёт выигрыша, поскольку большую часть времени они всё равно будут простаивать.
Напротив, работа GPU относительно простая. Она заключается в принятии группы полигонов с одной стороны и генерации группы пикселей с другой. Полигоны и пиксели независимы друг от друга, поэтому их можно обрабатывать параллельно. Таким образом, в GPU можно выделить крупную часть кристалла на вычислительные блоки, которые, в отличие от CPU, будут реально использоваться.
 |
Нажмите на картинку для увеличения.
GPU отличается от CPU не только этим. Доступ к памяти в GPU очень связанный - если считывается тексель, то через несколько тактов будет считываться соседний тексель; когда записывается пиксель, то через несколько тактов будет записываться соседний. Разумно организуя память, можно получить производительность, близкую к теоретической пропускной способности. Это означает, что GPU, в отличие от CPU, не требуется огромного кэша, поскольку его роль заключается в ускорении операций текстурирования. Всё, что нужно, это несколько килобайт, содержащих несколько текселей, используемых в билинейных и трилинейных фильтрах.
|
Нажмите на картинку для увеличения.
Да здравствует GeForce FX!
Два мира долгое время оставались разделёнными. Мы использовали CPU (или даже несколько CPU) для офисных задач и интернет-приложений, а GPU хорошо подходили лишь для ускорения визуализации. Но одна особенность изменила всё: а именно, появление программируемых GPU. Поначалу центральным процессорам было нечего бояться. Первые так называемые программируемые GPU (NV20 и R200) вряд ли представляли угрозу. Число инструкций в программе оставалось ограниченным около 10, они работали над весьма экзотическими типами данных, такими как 9- или 12-битными числами с фиксированной запятой.
 |
Нажмите на картинку для увеличения.
Но закон Мура вновь показал себя с лучшей стороны. Увеличение числа транзисторов не только позволило повысить количество вычислительных блоков, но и улучшило их гибкость. Появление NV30 можно считать существенным шагом вперёд по нескольким причинам. Конечно, геймерам карты NV30 не очень понравились, однако новые графические процессоры стали опираться на две особенности, которые были призваны изменить восприятие GPU уже не только как графических акселераторов.
- Поддержка вычислений с плавающей запятой одинарной точности (пусть даже это и не соответствовало стандарту IEEE754);
- поддержка числа инструкций больше тысячи.
Вот мы и получили все условия, которые способны привлечь исследователей-первопроходцев, всегда желающих получить дополнительную вычислительную мощность.
Идея использования графических акселераторов для математических расчётов не нова. Первые попытки были сделаны ещё в 90-х годах прошлого века. Конечно, они были очень примитивными - ограничиваясь, по большей части, использованием некоторых аппаратно заложенных функций, например, растеризации и Z-буферов для ускорения таких задач, как поиск маршрута или вывод диаграмм Вороного .

 |
Нажмите на картинку для увеличения.
В 2003 году, с появлением эволюционировавших шейдеров, была достигнута новая планка - на этот раз выполнение матричных вычислений. Это был год, когда целая секция SIGGRAPH ("Computations on GPUs/Вычисления на GPU") была выделена под новую область ИТ. Эта ранняя инициатива получила название GPGPU (General-Purpose computation on GPU, универсальные вычисления на GPU). И ранним поворотным моментом стало появление .
Чтобы понять роль BrookGPU, нужно разобраться, как всё происходило до его появления. Единственным способом получить ресурсы GPU в 2003 году было использование одного из двух графических API - Direct3D или OpenGL. Следовательно, разработчикам, которые хотели получить возможности GPU для своих вычислений, приходилось опираться на два упомянутых API. Проблема в том, что они не всегда являлись экспертами в программировании видеокарт, а это серьёзно осложняло доступ к технологиям. Если 3D-программисты оперируют шейдерами, текстурами и фрагментами, то специалисты в области параллельного программирования опираются на потоки, ядра, разбросы и т.д. Поэтому сначала нужно было привести аналогии между двумя мирами.
- Поток (stream) представляет собой поток элементов одного типа, в GPU он может быть представлен текстурой. В принципе, в классическом программировании есть такой аналог, как массив.
- Ядро (kernel) - функция, которая будет применяться независимо к каждому элементу потока; является эквивалентом пиксельного шейдера. В классическом программировании можно привести аналогию цикла - он применяется к большому числу элементов.
- Чтобы считывать результаты применения ядра к потоку, должна быть создана текстура. На CPU эквивалента нет, поскольку там есть полный доступ к памяти.
- Управление местоположением в памяти, куда будет производиться запись (в операциях разброса/scatter), осуществляется через вершинный шейдер, поскольку пиксельный шейдер не может изменять координаты обрабатываемого пикселя.


Как можно видеть, даже с учётом приведённых аналогий, задача не выглядит простой. И на помощь пришёл Brook. Под этим названием подразумеваются расширения к языку C ("C with streams", "C с потоками"), как назвали их разработчики в Стэнфорде. По своей сути, задача Brook сводилась к сокрытию от программиста всех составляющих 3D API, что позволяло представить GPU как сопроцессор для параллельных вычислений. Для этого компилятор Brook обрабатывал файл.br с кодом C++ и расширениями, после чего генерировал код C++, который привязывался к библиотеке с поддержкой разных выходов (DirectX, OpenGL ARB, OpenGL NV3x, x86).
 |
Нажмите на картинку для увеличения.
У Brook есть несколько заслуг, первая из которых заключается в выводе GPGPU из тени, чтобы с этой технологией могли знакомиться и широкие массы. Хотя после объявления о проекте ряд ИТ-сайтов слишком оптимистично сообщил о том, что выход Brook ставит под сомнение существование CPU, которые вскоре будут заменены более мощными GPU. Но, как видим, и через пять лет этого не произошло. Честно говоря, мы не думаем, что это вообще когда-либо случится. С другой стороны, глядя на успешную эволюцию CPU, которые всё более ориентируются в сторону параллелизма (больше ядер, технология многопоточности SMT, расширение блоков SIMD), а также и на GPU, которые, напротив, становятся всё более универсальными (поддержка расчётов с плавающей запятой одинарной точности, целочисленные вычисления, поддержка расчётов с двойной точностью), похоже, что GPU и CPU вскоре попросту сольются. Что же тогда произойдёт? Будут ли GPU поглощены CPU, как в своё время произошло с математическими сопроцессорами? Вполне возможно. Intel и AMD сегодня работают над подобными проектами. Но ещё очень многое может измениться.

Но вернёмся к нашей теме. Преимущество Brook заключалось в популяризации концепции GPGPU, он существенно упростил доступ к ресурсам GPU, что позволило всё большим пользователям осваивать новую модель программирования. С другой стороны, несмотря на все качества Brook, предстоял ещё долгий путь, прежде чем ресурсы GPU можно будет использовать для вычислений.
Одна из проблем связана с разными уровнями абстракции, а также, в частности, с чрезмерной дополнительной нагрузкой, создаваемой 3D API, которая может быть весьма ощутима. Но более серьёзной можно считать проблему совместимости, с которой разработчики Brook ничего не могли сделать. Между производителями GPU существует жёсткая конкуренция, поэтому они нередко оптимизируют свои драйверы. Если подобные оптимизации, по большей части, хороши для геймеров, они могут в один момент покончить с совместимостью Brook. Поэтому сложно представить использование этого API в промышленном коде, который будет где-то работать. И долгое время Brook оставался уделом исследователей-любителей и программистов.
Однако успеха Brook оказалось достаточно, чтобы привлечь внимание ATI и nVidia, у них зародился интерес к подобной инициативе, поскольку она могла бы расширить рынок, открыв для компаний новый немаловажный сектор.
Исследователи, изначально вовлечённые в проект Brook, быстро присоединились к командам разработчиков в Санта-Кларе, чтобы представить глобальную стратегию для развития нового рынка. Идея заключалась в создании комбинации аппаратного и программного обеспечения, подходящего для задач GPGPU. Поскольку разработчики nVidia знают все секреты своих GPU, то на графическое API можно было и не опираться, а связываться с графическим процессором через драйвер. Хотя, конечно, при этом возникают свои проблемы. Итак, команда разработчиков CUDA (Compute Unified Device Architecture) создала набор программных уровней для работы с GPU.
 |
Нажмите на картинку для увеличения.
Как можно видеть на диаграмме, CUDA обеспечивает два API.
- Высокоуровневый API: CUDA Runtime API;
- низкоуровневый API: CUDA Driver API.
Поскольку высокоуровневый API реализован над низкоуровневым, каждый вызов функции уровня Runtime разбивается на более простые инструкции, которые обрабатывает Driver API. Обратите внимание, что два API взаимно исключают друг друга: программист может использовать один или другой API, но смешивать вызовы функций двух API не получится. Вообще, термин "высокоуровневый API" относителен. Даже Runtime API таков, что многие сочтут его низкоуровневым; впрочем, он всё же предоставляет функции, весьма удобные для инициализации или управления контекстом. Но не ожидайте особо высокого уровня абстракции - вам всё равно нужно обладать хорошим набором знаний о nVidia GPU и о том, как они работают.

С Driver API работать ещё сложнее; для запуска обработки на GPU вам потребуется больше усилий. С другой стороны, низкоуровневый API более гибок, предоставляя программисту дополнительный контроль, если нужно. Два API способны работать с ресурсами OpenGL или Direct3D (только девятая версия на сегодня). Польза от такой возможности очевидна - CUDA может использоваться для создания ресурсов (геометрия, процедурные текстуры и т.д.), которые можно передать на графическое API или, наоборот, можно сделать так, что 3D API будет отсылать результаты рендеринга программе CUDA, которая, в свою очередь, будет выполнять пост-обработку. Есть много примеров таких взаимодействий, и преимущество заключается в том, что ресурсы продолжают храниться в памяти GPU, их не требуется передавать через шину PCI Express, которая по-прежнему остаётся "узким местом".

Впрочем, следует отметить, что совместное использование ресурсов в видеопамяти не всегда проходит идеально и может привести к некоторым "головным болям". Например, при смене разрешения или глубины цвета, графические данные приоритетны. Поэтому если требуется увеличить ресурсы в кадровом буфере, то драйвер без проблем сделает это за счёт ресурсов приложений CUDA, которые попросту "вылетят" с ошибкой. Конечно, не очень элегантно, но такая ситуация не должна случаться очень уж часто. И раз уж мы начали говорить о недостатках: если вы хотите использовать несколько GPU для приложений CUDA, то вам нужно сначала отключить режим SLI, иначе приложения CUDA смогут "видеть" только один GPU.

Наконец, третий программный уровень отдан библиотекам - двум, если быть точным.
- CUBLAS, где есть необходимые блоки для вычислений линейной алгебры на GPU;
- CUFFT, которая поддерживает расчёт преобразований Фурье - алгоритм, широко используемый в области обработки сигналов.
Перед тем, как мы погрузимся в CUDA, позвольте определить ряд терминов, разбросанных по документации nVidia. Компания выбрала весьма специфическую терминологию, к которой трудно привыкнуть. Прежде всего, отметим, что поток (thread) в CUDA имеет далеко не такое же значение, как поток CPU, а также и не является эквивалентом потока в наших статьях о GPU. Поток GPU в данном случае является базовый набор данных, которые требуется обработать. В отличие от потоков CPU, потоки CUDA очень "лёгкие", то есть переключение контекста между двумя потоками - отнюдь не ресурсоёмкая операция.
Второй термин, часто встречающийся в документации CUDA - варп (warp)
. Здесь путаницы нет, поскольку в русском языке аналога не существует (разве что вы не являетесь фанатом Start Trek или игры Warhammer). На самом деле термин взят из текстильной промышленности, где через основную пряжу (warp yarn), которая растянута на станке, протягивается уточная пряжа (weft yarn). Варп в CUDA представляет собой группу из 32 потоков и является минимальным объёмом данных, обрабатываемых SIMD-способом в мультипроцессорах CUDA.

Но подобная "зернистость" не всегда удобна для программиста. Поэтому в CUDA, вместо работы с варпами напрямую, можно работать с блоками/block , содержащими от 64 до 512 потоков.
Наконец, эти блоки собираются вместе в сетки/grid
. Преимущество подобной группировки заключается в том, что число блоков, одновременно обрабатываемых GPU, тесно связано с аппаратными ресурсами, как мы увидим ниже. Группировка блоков в сетки позволяет полностью абстрагироваться от этого ограничения и применить ядро/kernel к большему числу потоков за один вызов, не думая о фиксированных ресурсах. За всё это отвечают библиотеки CUDA. Кроме того, подобная модель хорошо масштабируется. Если GPU имеет мало ресурсов, то он будет выполнять блоки последовательно. Если число вычислительных процессоров велико, то блоки могут выполняться параллельно. То есть, один и тот же код может работать на GPU как начального уровня, так и на топовых и даже будущих моделях.

Есть ещё пара терминов в CUDA API, которые обозначают CPU (хост/host ) и GPU (устройство/device ). Если это небольшое введение вас не испугало, то настало время поближе познакомиться с CUDA.
Если вы регулярно читаете Tom"s Hardware Guide, то архитектура последних GPU от nVidia вам знакома. Если нет, мы рекомендуем ознакомиться со статьёй "nVidia GeForce GTX 260 и 280: новое поколение видеокарт
". Что касается CUDA, то nVidia представляет архитектуру несколько по-другому, демонстрируя некоторые детали, раньше остававшиеся скрытыми.

Как можно видеть по иллюстрации выше, ядро шейдеров nVidia состоит из нескольких кластеров текстурных процессоров (Texture Processor Cluster, TPC) . Видеокарта 8800 GTX, например, использовала восемь кластеров, 8800 GTS - шесть и т.д. Каждый кластер, по сути, состоит из текстурного блока и двух потоковых мультипроцессоров (streaming multiprocessor) . Последние включают начало конвейера (front end), выполняющее чтение и декодирование инструкций, а также отсылку их на выполнение, и конец конвейера (back end), состоящий из восьми вычислительных устройств и двух суперфункциональных устройств SFU (Super Function Unit) , где инструкции выполняются по принципу SIMD, то есть одна инструкция применяется ко всем потокам в варпе. nVidia называет такой способ выполнения SIMT (single instruction multiple threads, одна инструкция, много потоков). Важно отметить, что конец конвейера работает на частоте в два раза превосходящей его начало. На практике это означает, что данная часть выглядит в два раза "шире", чем она есть на самом деле (то есть как 16-канальный блок SIMD вместо восьмиканального). Потоковые мультипроцессоры работают следующим образом: каждый такт начало конвейера выбирает варп, готовый к выполнению, и запускает выполнение инструкции. Чтобы инструкция применилась ко всем 32 потокам в варпе, концу конвейера потребуется четыре такта, но поскольку он работает на удвоенной частоте по сравнению с началом, потребуется только два такта (с точки зрения начала конвейера). Поэтому, чтобы начало конвейера не простаивало такт, а аппаратное обеспечение было максимально загружено, в идеальном случае можно чередовать инструкции каждый такт - классическая инструкция в один такт и инструкция для SFU - в другой.
Каждый мультипроцессор обладает определённым набором ресурсов, в которых стоит разобраться. Есть небольшая область памяти под названием "Общая память/Shared Memory" , по 16 кбайт на мультипроцессор. Это отнюдь не кэш-память: программист может использовать её по своему усмотрению. То есть, перед нами что-то близкое к Local Store у SPU на процессорах Cell. Данная деталь весьма любопытная, поскольку она подчёркивает, что CUDA - это комбинация программных и аппаратных технологий. Данная область памяти не используется для пиксельных шейдеров, что nVidia остроумно подчёркивает "нам не нравится, когда пиксели разговаривают друг с другом".
Данная область памяти открывает возможность обмена информацией между потоками в одном блоке
. Важно подчеркнуть это ограничение: все потоки в блоке гарантированно выполняются одним мультипроцессором. Напротив, привязка блоков к разным мультипроцессорам вообще не оговаривается, и два потока из разных блоков не могут обмениваться информацией между собой во время выполнения. То есть пользоваться общей памятью не так и просто. Впрочем, общая память всё же оправданна за исключением случаев, когда несколько потоков попытаются обратиться к одному банку памяти, вызывая конфликт. В остальных ситуациях доступ к общей памяти такой же быстрый, как и к регистрам.

Общая память - не единственная, к которой могут обращаться мультипроцессоры. Они могут использовать видеопамять, но с меньшей пропускной способностью и большими задержками. Поэтому, чтобы снизить частоту обращения к этой памяти, nVidia оснастила мультипроцессоры кэшем (примерно 8 кбайт на мультипроцессор), хранящим константы и текстуры.

Мультипроцессор имеет 8 192 регистра, которые общие для всех потоков всех блоков, активных на мультипроцессоре. Число активных блоков на мультипроцессор не может превышать восьми, а число активных варпов ограничено 24 (768 потоков). Поэтому 8800 GTX может обрабатывать до 12 288 потоков в один момент времени. Все эти ограничения стоило упомянуть, поскольку они позволяют оптимизировать алгоритм в зависимости от доступных ресурсов.
Оптимизация программы CUDA, таким образом, состоит в получении оптимального баланса между количеством блоков и их размером. Больше потоков на блок будут полезны для снижения задержек работы с памятью, но и число регистров, доступных на поток, уменьшается. Более того, блок из 512 потоков будет неэффективен, поскольку на мультипроцессоре может быть активным только один блок, что приведёт к потере 256 потоков. Поэтому nVidia рекомендует использовать блоки по 128 или 256 потоков, что даёт оптимальный компромисс между снижением задержек и числом регистров для большинства ядер/kernel.
С программной точки зрения CUDA состоит из набора расширений к языку C, что напоминает BrookGPU, а также нескольких специфических вызовов API. Среди расширений присутствуют спецификаторы типа, относящиеся к функциям и переменным. Важно запомнить ключевое слово __global__ , которое, будучи приведённым перед функцией, показывает, что последняя относится к ядру/kernel - эту функцию будет вызывать CPU, а выполняться она будет на GPU. Префикс __device__ указывает, что функция будет выполняться на GPU (который, кстати, CUDA и называет "устройство/device") но она может быть вызвана только с GPU (иными словами, с другой функции __device__ или с функции __global__). Наконец, префикс __host__ опционален, он обозначает функцию, которая вызывается CPU и выполняется CPU - другими словами, обычную функцию.
Есть ряд ограничений, связанных с функциями __device__ и __global__: они не могут быть рекурсивными (то есть вызывать самих себя), и не могут иметь переменное число аргументов. Наконец, поскольку функции __device__ располагаются в пространстве памяти GPU, вполне логично, что получить их адрес не удастся. Переменные тоже имеют ряд квалификаторов, которые указывают на область памяти, где они будут храниться. Переменная с префиксом __shared__
означает, что она будет храниться в общей памяти потокового мультипроцессора. Вызов функции __global__ немного отличается. Дело в том, при вызове нужно задать конфигурацию выполнения - более конкретно, размер сетки/grid, к которой будет применено ядро/kernel, а также размер каждого блока. Возьмём, например, ядро со следующей подписью.
| __global__ void Func(float* parameter); |
Оно будет вызываться в виде
| Func<<< Dg, Db >>> (parameter); |
где Dg является размером сетки, а Db - размером блока. Две этих переменных относятся к новому типу вектора, появившегося с CUDA.
API CUDA содержит функции для работы с памятью в VRAM: cudaMalloc для выделения памяти, cudaFree для освобождения и cudaMemcpy для копирования памяти между RAM и VRAM и наоборот.
Мы закончим данный обзор весьма интересным способом, которым компилируется программа CUDA: компиляция выполняется в несколько этапов. Сначала извлекается код, относящийся к CPU, который передаётся стандартному компилятору. Код, предназначенный для GPU, сначала преобразовывается в промежуточный язык PTX. Он подобен ассемблеру и позволяет изучать код в поисках потенциальных неэффективных участков. Наконец, последняя фаза заключается в трансляции промежуточного языка в специфические команды GPU и создании двоичного файла.

Просмотрев документацию nVidia, так и хочется попробовать CUDA на неделе. Действительно, что может быть лучше оценки API путём создания собственной программы? Именно тогда большинство проблем должны выплыть на поверхность, пусть даже на бумаге всё выглядит идеально. Кроме того, практика лучше всего покажет, насколько хорошо вы поняли все принципы, изложенные в документации CUDA.
В подобный проект погрузиться довольно легко. Сегодня для скачивания доступно большое количество бесплатных, но качественных инструментов. Для нашего теста мы использовали Visual C++ Express 2005, где есть всё необходимое. Самое сложное заключалось в том, чтобы найти программу, портирование которой на GPU не заняло бы несколько недель, и вместе с тем она была бы достаточно интересная, чтобы наши усилия не пропали даром. В конце концов, мы выбрали отрезок кода, который берёт карту высот и рассчитывает соответствующую карту нормалей. Мы не будем детально углубляться в эту функцию, поскольку в данной статье это вряд ли интересно. Если быть кратким, то программа занимается искривлением участков: для каждого пикселя начального изображения мы накладываем матрицу, определяющую цвет результирующего пикселя в генерируемом изображении по прилегающим пикселям, используя более или менее сложную формулу. Преимущество этой функции в том, что её очень легко распараллелить, поэтому данный тест прекрасно показывает возможности CUDA.


Ещё одно преимущество заключается в том, что у нас уже есть реализация на CPU, поэтому мы можем сравнивать её результат с версией CUDA - и не изобретать колесо заново.
Ещё раз повторим, что целью теста являлось знакомство с утилитами CUDA SDK, а не сравнительное тестирование версий под CPU и GPU. Поскольку это была первая наша попытка создания программы CUDA, мы не особо надеялись получить высокую производительность. Так как данная часть кода не является критической, то версия под CPU была не оптимизирована, поэтому прямое сравнение результатов вряд ли интересно.
Производительность
Однако мы замерили время выполнения, чтобы посмотреть, есть ли преимущество в использовании CUDA даже с самой грубой реализацией, или нам потребуется длительная и утомительная практика, чтобы получить какой-то выигрыш при использовании GPU. Тестовая машина была взята из нашей лаборатории разработки - ноутбук с процессором Core 2 Duo T5450 и видеокартой GeForce 8600M GT, работающей под Vista. Это далеко не суперкомпьютер, но результаты весьма интересны, поскольку тест не "заточен" под GPU. Всегда приятно видеть, когда nVidia демонстрирует огромный прирост на системах с монстрообразными GPU и немалой пропускной способностью, но на практике многие из 70 миллионов GPU с поддержкой CUDA на современном рынке ПК далеко не такие мощные, поэтому и наш тест имеет право на жизнь.
Для изображения 2 048 x 2 048 пикселей мы получили следующие результаты.
- CPU 1 поток: 1 419 мс;
- CPU 2 потока: 749 мс;
- CPU 4 потока: 593 мс
- GPU (8600M GT) блоки по 256 потоков: 109 мс;
- GPU (8600M GT) блоки по 128 потоков: 94 мс;
- GPU (8800 GTX) блоки по 128 потоков/ 256 потоков: 31 мс.
По результатам можно сделать несколько выводов. Начнём с того, что, несмотря на разговоры об очевидной лени программистов, мы модифицировали начальную версию CPU под несколько потоков. Как мы уже упоминали, код идеален для этой ситуации - всё, что требуется, это разбить начальное изображение на столько зон, сколько существует потоков. Обратите внимание, что от перехода от одного потока на два на нашем двуядерном CPU ускорение получилось почти линейное, что тоже указывает на параллельную природу тестовой программы. Весьма неожиданно, но версия с четырьмя потоками тоже оказалась быстрее, хотя на нашем процессоре это весьма странно - можно было, напротив, ожидать падения эффективности из-за накладных расходов на управление дополнительными потоками. Как можно объяснить такой результат? Сложно сказать, но, возможно, виновен планировщик потоков под Windows; в любом случае, результат повторяем. С текстурами меньшего размера (512x512) прирост от разделения на потоки был не такой выраженный (примерно 35% против 100%), и поведение версии с четырьмя потоками было логичнее, без прироста по сравнению с версией на два потока. GPU работал всё ещё быстрее, но уже не так выражено (8600M GT была в три раза быстрее, чем версия с двумя потоками).
 |
Нажмите на картинку для увеличения.
Второе значимое наблюдение - даже самая медленная реализация GPU оказалась почти в шесть раз быстрее, чем самая производительная версия CPU. Для первой программы и неоптимизированной версии алгоритма результат очень даже ободряющий. Обратите внимание, что мы получили ощутимо лучший результат на небольших блоках, хотя интуиция может подсказывать об обратном. Объяснение простое - наша программа использует 14 регистров на поток, и с 256-поточными блоками требуется 3 584 регистра на блок, а для полной нагрузки процессора требуется 768 потоков, как мы показывали. В нашем случае это составляет три блока или 10 572 регистра. Но мультипроцессор имеет всего 8 192 регистра, поэтому он может поддерживать активными только два блока. Напротив, с блоками по 128 потоков нам требуется 1 792 регистра на блок; если 8 192 поделить на 1 792 и округлить до ближайшего целого, то мы получим четыре блока. На практике число потоков будет таким же (512 на мультипроцессор, хотя для полной нагрузки теоретически нужно 768), но увеличение числа блоков даёт GPU преимущество гибкости по доступу к памяти - когда идёт операция с большими задержками, то можно запустить выполнение инструкций другого блока, ожидая поступления результатов. Четыре блока явно снижают задержки, особенно с учётом того, что наша программа использует несколько доступов в память.
Анализ
Наконец, несмотря на то, что мы сказали выше, мы не смогли устоять перед искушением и запустили программу на 8800 GTX, которая оказалась в три раза быстрее 8600, независимо от размера блоков. Можно подумать, что на практике на соответствующих архитектурах результат будет в четыре или более раз выше: 128 АЛУ/шейдерных процессоров против 32 и более высокая тактовая частота (1,35 ГГц против 950 МГц), но так не получилось. Скорее всего, ограничивающим фактором оказался доступ к памяти. Если быть более точным, доступ к начальному изображению осуществляется как к многомерному массиву CUDA - весьма сложный термин для того, что является не более, чем текстурой. Но ест несколько преимуществ.
- доступы выигрывают от кэша текстур;
- мы используем wrapping mode, в котором не нужно обрабатывать границы изображения, в отличие от версии CPU.
Кроме того, мы можем получить преимущество от "бесплатной" фильтрации с нормализованной адресацией между вместо и , но в нашем случае это вряд ли полезно. Как вы знаете, 8600 оснащён 16 текстурными блоками по сравнению с 32 у 8800 GTX. Поэтому между двумя архитектурами соотношение всего два к одному. Добавьте к этому разницу в частотах, и мы получим соотношение (32 x 0,575) / (16 x 0,475) = 2,4 - близко к "трём к одному", что мы получили на самом деле. Данная теория также объясняет, почему размер блоков многое на G80 не меняет, поскольку АЛУ всё равно упирается в текстурные блоки.
 |
Нажмите на картинку для увеличения.
Кроме многообещающих результатов, наше первое знакомство с CUDA прошло очень хорошо, учитывая не самые благоприятные выбранные условия. Разработка на ноутбуке под Vista подразумевает, что придётся использовать CUDA SDK 2.0, всё ещё находящееся в состоянии бета-версии, с драйвером 174.55, который тоже бета-версия. Несмотря на это мы не можем сообщить о каких-либо неприятных сюрпризах - только начальные ошибки во время первой отладки, когда наша программа, всё ещё весьма "глючная" попыталась адресовать память за пределами выделенного пространства.
Монитор начал дико мерцать, затем экран почернел... пока Vista не запустила службу восстановления драйвера, и всё стало в порядке. Но всё же несколько удивительно это наблюдать, если вы привыкли видеть типичную ошибку Segmentation Fault на стандартных программах, подобно нашей. Наконец, небольшая критика в сторону nVidia: во всей документации, доступной для CUDA, нет небольшого руководства, которое бы шаг за шагом рассказывало о том, как настроить окружение разработки под Visual Studio. Собственно, проблема невелика, поскольку в SDK есть полный набор примеров, которые можно изучить для понимания каркаса для приложений CUDA, но руководство для новичков не помешало бы.
 |
Нажмите на картинку для увеличения.
nVidia представила CUDA с выпуском GeForce 8800. И в то время обещания казались весьма соблазнительными, но мы придержали свой энтузиазм до реальной проверки. Действительно, в то время это казалось больше разметкой территории, чтобы оставаться на волне GPGPU. Без доступного SDK сложно сказать, что перед нами не очередная маркетинговая пустышка, из которой ничего не получится. Уже не в первый раз хорошая инициатива была объявлена слишком рано и в то время не вышла на свет из-за недостатка поддержки - особенно в столь конкурентном секторе. Теперь, через полтора года после объявления, мы с уверенностью можем сказать, что nVidia сдержала слово.

SDK довольно быстро появился в бета-версии в начале 2007 года, с тех пор он быстро обновлялся, что доказывает значимость этого проекта для nVidia. Сегодня CUDA весьма приятно развивается: SDK доступен уже в бета-версии 2.0 для основных операционных систем (Windows XP и Vista, Linux, а также 1.1 для Mac OS X), а для разработчиков nVidia выделила целый раздел сайта.


На более профессиональном уровне впечатление от первых шагов с CUDA оказалось очень даже позитивным. Если даже вы знакомы с архитектурой GPU, вы легко разберётесь. Когда API выглядит понятным с первого взгляда, то сразу же начинаешь полагать, что получишь убедительные результаты. Но не будет ли теряться вычислительное время от многочисленных передач с CPU на GPU? И как использовать эти тысячи потоков практически без примитива синхронизации? Мы начинали наши эксперименты со всеми этими опасениями в уме. Но они быстро рассеялись, когда первая версия нашего алгоритма, пусть и весьма тривиального, оказалась существенно быстрее, чем на CPU.
Так что CUDA - это не "палочка-выручалочка" для исследователей, которые хотят убедить руководство университета купить им GeForce. CUDA - уже полностью доступная технология, которую может использовать любой программист со знанием C, если он готов потратить время и усилия на привыкание к новой парадигме программирования. Эти усилия не будут потеряны даром, если ваши алгоритмы хорошо распараллеливаются. Также мы хотели бы поблагодарить nVidia за предоставление полной и качественной документации, где найдут ответы начинающие программисты CUDA.
Что же требуется CUDA, чтобы стать узнаваемым API? Если говорить одним словом: переносимость. Мы знаем, что будущее ИТ кроется в параллельных вычислениях - сегодня уже каждый готовится к подобным изменениям, и все инициативы, как программные, так и аппаратные, направлены в этом направлении. Однако на данный момент, если смотреть на развитие парадигм, мы находится ещё на начальном этапе: мы создаём потоки вручную и стараемся спланировать доступ к общим ресурсам; со всем этим ещё как-то можно справиться, если количество ядер можно пересчитать по пальцам одной руки. Но через несколько лет, когда число процессоров будет исчисляться сотнями, такой возможности уже не будет. С выпуском CUDA nVidia сделала первый шаг в решении этой проблемы - но, конечно, данное решение подходит только для GPU от этой компании, да и то не для всех. Только GF8 и 9 (и их производные Quadro/Tesla) сегодня могут работать с программами CUDA. И новая линейка 260/280, конечно.

 |
Нажмите на картинку для увеличения.
nVidia может хвастаться тем, что продала 70 миллионов CUDA-совместимых GPU по всему миру, но этого всё равно мало, чтобы стать стандартом де-факто. С учётом того, что конкуренты не сидят, сложа руки. AMD предлагает собственный SDK (Stream Computing), да и Intel объявила о решении (Ct), хотя оно ещё не доступно. Грядёт война стандартов, и на рынке явно не будет места для трёх конкурентов, пока другой игрок, например, Microsoft, не выйдет с предложением общего API, что, конечно, облегчит жизнь разработчикам.

Поэтому у nVidia есть немало трудностей на пути утверждения CUDA. Хотя технологически перед нами, без сомнения, успешное решение, ещё остаётся убедить разработчиков в его перспективах - и это будет сделать нелегко. Впрочем, судя по многим недавним объявлениям и новостям по поводу API, будущее выглядит отнюдь не печальным.
И предназначен для трансляции host-кода (главного, управляющего кода) и device-кода (аппаратного кода) (файлов с расширением.cu) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования, например в NetBeans .
В архитектуре CUDA используется модель памяти грид , кластерное моделирование потоков и SIMD -инструкции. Применима не только для высокопроизводительных графических вычислений, но и для различных научных вычислений с использованием видеокарт nVidia. Ученые и исследователи широко используют CUDA в различных областях, включая астрофизику , вычислительную биологию и химию, моделирование динамики жидкостей, электромагнитных взаимодействий, компьютерную томографию, сейсмический анализ и многое другое. В CUDA имеется возможность подключения к приложениям, использующим OpenGL и Direct3D . CUDA - кроссплатформенное программное обеспечение для таких операционных систем как Linux , Mac OS X и Windows .
22 марта 2010 года nVidia выпустила CUDA Toolkit 3.0, который содержал поддержку OpenCL .
Оборудование
Платформа CUDA Впервые появились на рынке с выходом чипа NVIDIA восьмого поколения G80 и стала присутствовать во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce , Quadro и NVidia Tesla .
Первая серия оборудования, поддерживающая CUDA SDK, G8x, имела 32-битный векторный процессор одинарной точности , использующий CUDA SDK как API (CUDA поддерживает тип double языка Си, однако сейчас его точность понижена до 32-битного с плавающей запятой). Более поздние процессоры GT200 имеют поддержку 64-битной точности (только для SFU), но производительность значительно хуже, чем для 32-битной точности (из-за того, что SFU всего два на каждый потоковый мультипроцессор, а скалярных процессоров - восемь). Графический процессор организует аппаратную многопоточность, что позволяет задействовать все ресурсы графического процессора. Таким образом, открывается перспектива переложить функции физического ускорителя на графический ускоритель (пример реализации - nVidia PhysX). Также открываются широкие возможности использования графического оборудования компьютера для выполнения сложных неграфических вычислений: например, в вычислительной биологии и в иных отраслях науки.
Преимущества
По сравнению с традиционным подходом к организации вычислений общего назначения посредством возможностей графических API, у архитектуры CUDA отмечают следующие преимущества в этой области:
Ограничения
- Все функции, выполнимые на устройстве, не поддерживают рекурсии (в версии CUDA Toolkit 3.1 поддерживает указатели и рекурсию) и имеют некоторые другие ограничения
Поддерживаемые GPU и графические ускорители
Перечень устройств от производителя оборудования Nvidia с заявленной полной поддержкой технологии CUDA приведён на официальном сайте Nvidia: CUDA-Enabled GPU Products (англ.) .
Фактически же, в настоящее время на рынке аппаратных средств для ПК поддержку технологии CUDA обеспечивают следующие периферийные устройства :
| Версия спецификации | GPU | Видеокарты |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9600 GSO, 9800GTX/GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32/370M, 3/5/770M, 16/17/27/28/36/37/3800M, NVS420/50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S/M2050/70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF110) GTX 560 TI 448, GTX570, GTX580, GTX590 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti, GTX 650, GT 640, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 670MX, GTX 660M, GeForce GT 650M, GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- Модели Tesla C1060, Tesla S1070, Tesla C2050/C2070, Tesla M2050/M2070, Tesla S2050 позволяют производить вычисления на GPU с двойной точностью.
Особенности и спецификации различных версий
| Feature support (unlisted features are supported for all compute capabilities) |
Compute capability (version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
32-bit words in global memory |
Нет | Да | |||
floating point values in global memory |
|||||
| Integer atomic functions operating on 32-bit words in shared memory |
Нет | Да | |||
| atomicExch() operating on 32-bit floating point values in shared memory |
|||||
| Integer atomic functions operating on 64-bit words in global memory |
|||||
| Warp vote functions | |||||
| Double-precision floating-point operations | Нет | Да | |||
| Atomic functions operating on 64-bit integer values in shared memory |
Нет | Да | |||
| Floating-point atomic addition operating on 32-bit words in global and shared memory |
|||||
| _ballot() | |||||
| _threadfence_system() | |||||
| _syncthreads_count(), _syncthreads_and(), _syncthreads_or() |
|||||
| Surface functions | |||||
| 3D grid of thread block | |||||
| Technical specifications | Compute capability (version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| Maximum dimensionality of grid of thread blocks | 2 | 3 | |||
| Maximum x-, y-, or z-dimension of a grid of thread blocks | 65535 | ||||
| Maximum dimensionality of thread block | 3 | ||||
| Maximum x- or y-dimension of a block | 512 | 1024 | |||
| Maximum z-dimension of a block | 64 | ||||
| Maximum number of threads per block | 512 | 1024 | |||
| Warp size | 32 | ||||
| Maximum number of resident blocks per multiprocessor | 8 | ||||
| Maximum number of resident warps per multiprocessor | 24 | 32 | 48 | ||
| Maximum number of resident threads per multiprocessor | 768 | 1024 | 1536 | ||
| Number of 32-bit registers per multiprocessor | 8 K | 16 K | 32 K | ||
| Maximum amount of shared memory per multiprocessor | 16 KB | 48 KB | |||
| Number of shared memory banks | 16 | 32 | |||
| Amount of local memory per thread | 16 KB | 512 KB | |||
| Constant memory size | 64 KB | ||||
| Cache working set per multiprocessor for constant memory | 8 KB | ||||
| Cache working set per multiprocessor for texture memory | Device dependent, between 6 KB and 8 KB | ||||
| Maximum width for 1D texture |
8192 | 32768 | |||
| Maximum width for 1D texture reference bound to linear memory |
2 27 | ||||
| Maximum width and number of layers for a 1D layered texture reference |
8192 x 512 | 16384 x 2048 | |||
| Maximum width and height for 2D texture reference bound to linear memory or a CUDA array |
65536 x 32768 | 65536 x 65535 | |||
| Maximum width, height, and number of layers for a 2D layered texture reference |
8192 x 8192 x 512 | 16384 x 16384 x 2048 | |||
| Maximum width, height and depth for a 3D texture reference bound to linear memory or a CUDA array |
2048 x 2048 x 2048 | ||||
| Maximum number of textures that can be bound to a kernel |
128 | ||||
| Maximum width for a 1D surface reference bound to a CUDA array |
Not supported |
8192 | |||
| Maximum width and height for a 2D surface reference bound to a CUDA array |
8192 x 8192 | ||||
| Maximum number of surfaces that can be bound to a kernel |
8 | ||||
| Maximum number of instructions per kernel |
2 million | ||||
Пример
CudaArray* cu_array; texture< float , 2 > tex; // Allocate array cudaMalloc( & cu_array, cudaCreateChannelDesc< float> () , width, height ) ; // Copy image data to array cudaMemcpy( cu_array, image, width* height, cudaMemcpyHostToDevice) ; // Bind the array to the texture cudaBindTexture( tex, cu_array) ; // Run kernel dim3 blockDim(16 , 16 , 1 ) ; dim3 gridDim(width / blockDim.x , height / blockDim.y , 1 ) ; kernel<<< gridDim, blockDim, 0 >>> (d_odata, width, height) ; cudaUnbindTexture(tex) ; __global__ void kernel(float * odata, int height, int width) { unsigned int x = blockIdx.x * blockDim.x + threadIdx.x ; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y ; float c = texfetch(tex, x, y) ; odata[ y* width+ x] = c; }
Import pycuda.driver as drv import numpy drv.init () dev = drv.Device (0 ) ctx = dev.make_context () mod = drv.SourceModule (""" __global__ void multiply_them(float *dest, float *a, float *b) { const int i = threadIdx.x; dest[i] = a[i] * b[i]; } """ ) multiply_them = mod.get_function ("multiply_them" ) a = numpy.random .randn (400 ) .astype (numpy.float32 ) b = numpy.random .randn (400 ) .astype (numpy.float32 ) dest = numpy.zeros_like (a) multiply_them( drv.Out (dest) , drv.In (a) , drv.In (b) , block= (400 , 1 , 1 ) ) print dest-a*b
CUDA как предмет в вузах
По состоянию на декабрь 2009 года, программная модель CUDA преподается в 269 университетах по всему миру. В России обучающие курсы по CUDA читаются в Санкт-Петербургском политехническом университете , Ярославском государственном университете им. П. Г. Демидова , Московском , Нижегородском , Санкт-Петербургском , Тверском , Казанском , Новосибирском , Новосибирском государственном техническом университете Омском и Пермском государственных университетах, Международном университете природы общества и человека «Дубна» , Ивановском государственном энергетическом университете , Белгородский государственный университет , МГТУ им. Баумана , РХТУ им. Менделеева , Межрегиональном суперкомпьютерном центре РАН, . Кроме того, в декабре 2009 года было объявлено о начале работы первого в России научно-образовательного центра «Параллельные вычисления», расположенного в городе Дубна , в задачи которого входят обучение и консультации по решению сложных вычислительных задач на GPU.
На Украине курсы по CUDA читаются в Киевском институте системного анализа.
Ссылки
Официальные ресурсы
- CUDA Zone (рус.) - официальный сайт CUDA
- CUDA GPU Computing (англ.) - официальные веб-форумы, посвящённые вычислениям CUDA
Неофициальные ресурсы
Tom"s Hardware- Дмитрий Чеканов. nVidia CUDA: вычисления на видеокарте или смерть CPU? . Tom"s Hardware (22 июня 2008 г.). Архивировано
- Дмитрий Чеканов. nVidia CUDA: тесты приложений на GPU для массового рынка . Tom"s Hardware (19 мая 2009 г.). Архивировано из первоисточника 4 марта 2012. Проверено 19 мая 2009.
- Алексей Берилло. NVIDIA CUDA - неграфические вычисления на графических процессорах. Часть 1 . iXBT.com (23 сентября 2008 г.). Архивировано из первоисточника 4 марта 2012. Проверено 20 января 2009.
- Алексей Берилло. NVIDIA CUDA - неграфические вычисления на графических процессорах. Часть 2 . iXBT.com (22 октября 2008 г.). - Примеры внедрения NVIDIA CUDA. Архивировано из первоисточника 4 марта 2012. Проверено 20 января 2009.
- Боресков Алексей Викторович. Основы CUDA (20 января 2009 г.). Архивировано из первоисточника 4 марта 2012. Проверено 20 января 2009.
- Владимир Фролов. Введение в технологию CUDA . Сетевой журнал «Компьютерная графика и мультимедиа» (19 декабря 2008 г.). Архивировано из первоисточника 4 марта 2012. Проверено 28 октября 2009.
- Игорь Осколков. NVIDIA CUDA – доступный билет в мир больших вычислений . Компьютерра (30 апреля 2009 г.). Проверено 3 мая 2009.
- Владимир Фролов. Введение в технологию CUDA (1 августа 2009 г.). Архивировано из первоисточника 4 марта 2012. Проверено 3 апреля 2010.
- GPGPU.ru . Использование видеокарт для вычислений
- . Центр Параллельных Вычислений
Примечания
См. также
| Nvidia | ||||||||
|---|---|---|---|---|---|---|---|---|
| Графические процессоры |
| |||||||
В развитии современных процессоров намечается тенденция к постепенному увеличению количества ядер, что повышает их возможности в параллельных вычислениях. Однако уже давно имеются GPU, значительно превосходящие центральные процессоры в данном отношении. И эти возможности графических процессоров уже взяты на заметку некоторыми компаниями. Первые попытки использовать графические ускорители для нецелевых вычислений предпринимались еще с конца 90-х годов. Но только появление шейдеров стало толчком к развитию абсолютно новой технологии, и в 2003 году появилось понятие GPGPU (General-purpose graphics processing units). Немаловажную роль в развитии данной инициативы сыграл BrookGPU, который является специальным расширением для языка C. До появления BrookGPU программисты могли работать с GPU лишь через API Direct3D или OpenGL. Brook позволил разработчикам работать с привычной средой, а уже сам компилятор с помощью специальных библиотек реализовал взаимодействие с GPU на низком уровне.
Такой прогресс не мог не привлечь внимания лидеров данной индустрии - AMD и NVIDIA, которые занялись разработкой собственных программных платформ для неграфических вычислений на своих видеокартах. Никто лучше разработчиков GPU не знает в совершенстве все нюансы и особенности своих продуктов, что позволяет этим же компаниям максимально эффективно оптимизировать программный комплекс для конкретных аппаратных решений. На данный момент NVIDIA развивает платформу CUDA (Compute Unified Device Architecture), у AMD подобная технология именуется CTM (Close To Metal) или AMD Stream Computing. Мы рассмотрим некоторые возможности CUDA и на практике оценим вычислительные возможности графического чипа G92 видеокарты GeForce 8800 GT.
Но прежде рассмотрим некоторые нюансы выполнения расчетов при помощи графических процессоров. Основное преимущество их заключается в том, что графический чип изначально проектируется под выполнение множества потоков, а каждое ядро обычного CPU выполняет поток последовательных инструкций. Любой современный GPU является мультипроцессором, состоящим из нескольких вычислительных кластеров, с множеством ALU в каждом. Самый мощный современный чип GT200 состоит из 10 таких кластеров, на каждый из которых приходится 24 потоковых процессора. У тестируемой видеокарты GeForce 8800 GT на базе чипа G92 семь больших вычислительных блока по 16 потоковых процессоров. CPU используют SIMD блоки SSE для векторных вычислений (single instruction multiple data - одна инструкция выполняется над многочисленными данными), что требует трансформации данных в 4х векторы. GPU скалярно обрабатывает потоки, т.е. одна инструкция применяется над несколькими потоками (SIMT - single instruction multiple threads). Это избавляет разработчиков от преобразования данных в векторы, и допускает произвольные ветвления в потоках. Каждый вычислительный блок GPU имеет прямой доступ к памяти. Да и пропускная способность видеопамяти выше, благодаря использованию нескольких раздельных контроллеров памяти (на топовом G200 это 8 каналов по 64-бит) и высоких рабочих частот.
В целом, в определенных задачах при работе с большими объемами данных GPU оказываются намного быстрее CPU. Ниже вы видите иллюстрацию этого утверждения:
На диаграмме изображена динамика роста производительности CPU и GPU начиная с 2003 года. Данные эти любит приводить в качестве рекламы в своих документах NVIDIA, но они являются лишь теоретической выкладкой и на самом деле отрыв, конечно же, может оказаться намного меньше.
Но как бы там ни было, есть огромный потенциал графических процессоров, который можно использовать, и который требует специфического подхода к разработке программных продуктов. Все это реализовано в аппаратно-программной среде CUDA, которая состоит из нескольких программных уровней - высокоуровневый CUDA Runtime API и низкоуровневый CUDA Driver API.

CUDA использует для программирования стандартный язык C, что является одним из основных ее преимуществ для разработчиков. Изначально CUDA включает библиотеки BLAS (базовый пакет программ линейной алгебры) и FFT (расчёт преобразований Фурье). Также CUDA имеет возможность взаимодействия с графическими API OpenGL или DirectX, возможность разработки на низком уровне, характеризуется оптимизированным распределением потоков данных между CPU и GPU. Вычисления CUDA выполняются одновременно с графическими, в отличие от аналогичной платформы AMD, где для расчетов на GPU вообще запускается специальная виртуальная машина. Но такое «сожительство» чревато и возникновением ошибок в случае создания большой нагрузки графическим API при одновременной работе CUDA - ведь графические операции имеют все же более высокий приоритет. Платформа совместима с 32- и 64-битными операционными системами Windows XP, Windows Vista, MacOS X и различными версиями Linux. Платформа открытая и на сайте, кроме специальных драйверов для видеокарты, можно загрузить программные пакеты CUDA Toolkit, CUDA Developer SDK, включающие компилятор, отладчик, стандартные библиотеки и документацию.
Что же касается практической реализации CUDA, то длительное время эта технология использовалась лишь для узкоспециализированных математических вычислений в области физики элементарных частиц, астрофизики, медицины или прогнозирования изменений финансового рынка и т.п. Но данная технология становится постепенно ближе и к рядовым пользователям, в частности появляются специальные плагины для Photoshop, которые могут задействовать вычислительную мощность GPU. На специальной страничке можно изучить весь список программ, использующих возможности NVIDIA CUDA.
В качестве практических испытаний новой технологии на видеокарте MSI NX8800GT-T2D256E-OC мы воспользуемся программой TMPGEnc. Данный продукт является коммерческим (полная версия стоит $100), но к видеокартам MSI он поставляется в качестве бонуса в trial-версии сроком на 30 дней. Скачать данную версию можно и с сайта разработчика, но для установки TMPGEnc 4.0 XPress MSI Special Edition необходим оригинальный диск с драйверами от карты MSI - без него программа не инсталлируется.
Для отображения максимально полной информации о вычислительных возможностях в CUDA и сравнения с другими видеоадаптерами можно использовать специальную утилиту CUDA-Z. Вот какую информацию она выдает о нашей видеокарте GeForce 8800GT:
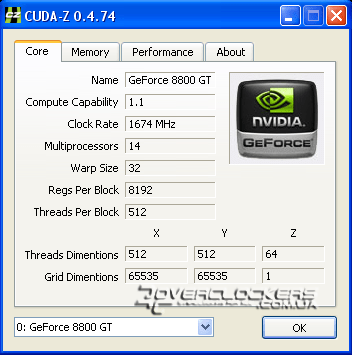


Относительно референсных моделей наш экземпляр работает на более высоких частотах: растровый домен на 63 МГц выше номинала, а шейдерные блоки быстрее на 174 МГц, память - на 100 МГц.
Мы сравним скорость конвертации одного и того же HD-видео при расчетах только с помощью CPU и при дополнительной активации CUDA в программе TMPGEnc на следующей конфигурации:
- Процессор: Pentium Dual-Core E5200 2,5 ГГц;
- Материнская плата: Gigabyte P35-S3;
- Память: 2х1GB GoodRam PC6400 (5-5-5-18-2T)
- Видеокарта: MSI NX8800GT-T2D256E-OC;
- Жесткий диск: 320GB WD3200AAKS;
- Блок питания: CoolerMaster eXtreme Power 500-PCAP;
- Операционная система: Windows XP SP2;
- TMPGEnc 4.0 XPress 4.6.3.268;
- Драйвера видеокарты: ForceWare 180.60.

Кодирование осуществлялось с помощью кодека DivX 6.8.4. В настройках качества этого кодека все значения оставлены по умолчанию, multithreading включен.

Поддержка многопоточности в TMPGEnc изначально включена во вкладке настроек CPU/GPU. В этом же разделе активируется и CUDA.
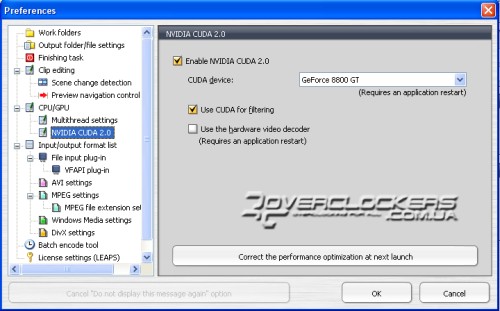
Как видно по приведенному скриншоту, активирована обработка фильтров с помощью CUDA, а аппаратный видеодекодер не включен. В документации к программе предупреждается, что активация последнего параметра приводит к увеличению времени обработки файла.
По итогам проведенных тестов получены следующие данные:

При частоте процессора 4 ГГц с активацией CUDA мы выиграли всего пару секунд (или 2%), что не особо впечатляет. А вот на более низкой частоте прирост от активации данной технологии позволяет сэкономить уже около 13% времени, что будет довольно ощутимо при обработке больших файлов. Но все равно результаты не столь впечатляющие, как ожидалось.
В программе TMPGEnc есть индикатор загрузки CPU и CUDA, в данной тестовой конфигурации он показывал загрузку центрального процессора примерно на 20%, а графического ядра на оставшиеся 80%. В итоге у нас те же 100%, что и при конвертации без CUDA и разницы по времени вообще может и не быть (но она все-таки есть). Небольшой объем памяти в 256 MB так же не является сдерживающим фактором. Судя по показаниям RivaTuner, в процессе работы использовалось не более 154 MB видеопамяти.

Выводы
Программа TMPGEnc является одной из тех, кто вводит технологию CUDA в массы. Использование GPU в данной программе позволяет ускорить процесс обработки видео и значительно разгрузить центральный процессор, что позволит пользователю комфортно заниматься и другими задачами в это же время. В нашем конкретном примере видеокарта GeForce 8800GT 256MB незначительно улучшила временные показатели при конвертации видео на базе разогнанного процессора Pentium Dual-Core E5200. Но отчетливо видно, что при снижении частоты увеличивается прирост от активации CUDA, на слабых процессорах прирост от ее использования будет намного больше. На фоне такой зависимости вполне логично предположить что и при увеличении нагрузки (например, использование очень большого количества дополнительных видео-фильтров) результаты системы с CUDA будут выделяется более значимой дельтой разницы затраченного времени на процесс кодирования. Также не стоит забывать, что и G92 на данный момент не самый мощный чип, и более современные видеокарты обеспечат значительно более высокую производительность в подобных приложениях. Однако в процессе работы приложения GPU загружен не полностью и, вероятно, распределение нагрузки зависит от каждой конфигурации отдельно, а именно от связки процессор/видеокарта, что в итоге может дать и больший (или меньший) прирост в процентном соотношении от активации CUDA. В любом случае, тем, кто работает с большими объемами видеоданных, такая технология все равно позволит значительно сэкономить свое время.
Правда, CUDA еще не обрела повсеместную популярность, качество программного обеспечения, работающего с этой технологией, требует доработок. В рассмотренной нами программе TMPGEnc 4.0 XPress данная технология не всегда работала. Один и тот же ролик можно было перекодировать несколько раз, а потом вдруг, при следующем запуске, загрузка CUDA уже была равна 0%. И это явление носило совершенно случайный характер на абсолютно разных операционных системах. Также рассмотренная программа отказывалась использовать CUDA при кодировании в формат XviD, но с популярным кодеком DivX никаких проблем не было.
В итоге пока технология CUDA позволяет ощутимо увеличить производительность персональных компьютеров лишь в определенных задачах. Но сфера применения подобной технологии будет расширяться, а процесс наращивания количества ядер в обычных процессорах свидетельствует о росте востребованности параллельных многопоточных вычислений в современных программных приложениях. Не зря в последнее время все лидеры индустрии загорелись идеей объединения CPU и GPU в рамках одной унифицированной архитектуры (вспомнить хотябы разрекламированный AMD Fusion). Возможно CUDA это один из этапов в процессе данного объединения.
Благодарим следующие компании за предоставленное тестовое оборудование:
Устройства для превращения персональных компьютеров в маленькие суперкомпьютеры известны довольно давно. Ещё в 80-х годах прошлого века на рынке предлагались так называемые транспьютеры, которые вставлялись в распространенные тогда слоты расширения ISA. Первое время их производительность в соответствующих задачах впечатляла, но затем рост быстродействия универсальных процессоров ускорился, они усилили свои позиции в параллельных вычислениях, и смысла в транспьютерах не осталось. Хотя подобные устройства существуют и сейчас это разнообразные специализированные ускорители. Но зачастую сфера их применения узка и особого распространения такие ускорители не получили.
Но в последнее время эстафета параллельных вычислений перешла к массовому рынку, так или иначе связанному с трёхмерными играми. Универсальные устройства с многоядерными процессорами для параллельных векторных вычислений, используемых в 3D-графике, достигают высокой пиковой производительности, которая универсальным процессорам не под силу. Конечно, максимальная скорость достигается лишь в ряде удобных задач и имеет некоторые ограничения, но такие устройства уже начали довольно широко применять в сферах, для которых они изначально и не предназначались. Отличным примером такого параллельного процессора является процессор Cell, разработанный альянсом Sony-Toshiba-IBM и применяемый в игровой приставке Sony PlayStation 3, а также и все современные видеокарты от лидеров рынка - компаний Nvidia и AMD.
Cell мы сегодня трогать не будем, хоть он и появился раньше и является универсальным процессором с дополнительными векторными возможностями, речь сегодня не о нём. Для 3D видеоускорителей ещё несколько лет назад появились первые технологии неграфических расчётов общего назначения GPGPU (General-Purpose computation on GPUs). Ведь современные видеочипы содержат сотни математических исполнительных блоков, и эта мощь может использоваться для значительного ускорения множества вычислительно интенсивных приложений. И нынешние поколения GPU обладают достаточно гибкой архитектурой, что вместе с высокоуровневыми языками программирования и программно-аппаратными архитектурами, подобными рассматриваемой в этой статье, раскрывает эти возможности и делает их значительно более доступными.
На создание GPCPU разработчиков побудило появление достаточно быстрых и гибких шейдерных программ, которые способны исполнять современные видеочипы. Разработчики задумали сделать так, чтобы GPU рассчитывали не только изображение в 3D приложениях, но и применялись в других параллельных расчётах. В GPGPU для этого использовались графические API: OpenGL и Direct3D, когда данные к видеочипу передавались в виде текстур, а расчётные программы загружались в виде шейдеров. Недостатками такого метода является сравнительно высокая сложность программирования, низкая скорость обмена данными между CPU и GPU и другие ограничения, о которых мы поговорим далее.
Вычисления на GPU развивались и развиваются очень быстро. И в дальнейшем, два основных производителя видеочипов, Nvidia и AMD, разработали и анонсировали соответствующие платформы под названием CUDA (Compute Unified Device Architecture) и CTM (Close To Metal или AMD Stream Computing), соответственно. В отличие от предыдущих моделей программирования GPU, эти были выполнены с учётом прямого доступа к аппаратным возможностям видеокарт. Платформы не совместимы между собой, CUDA это расширение языка программирования C, а CTM виртуальная машина, исполняющая ассемблерный код. Зато обе платформы ликвидировали некоторые из важных ограничений предыдущих моделей GPGPU, использующих традиционный графический конвейер и соответствующие интерфейсы Direct3D или OpenGL.
Конечно же, открытые стандарты, использующие OpenGL, кажутся наиболее портируемыми и универсальными, они позволяют использовать один и тот же код для видеочипов разных производителей. Но у таких методов есть масса недостатков, они значительно менее гибкие и не такие удобные в использовании. Кроме того, они не дают использовать специфические возможности определённых видеокарт, такие, как быстрая разделяемая (общая) память, присутствующая в современных вычислительных процессорах.
Именно поэтому компания Nvidia выпустила платформу CUDA C-подобный язык программирования со своим компилятором и библиотеками для вычислений на GPU. Конечно же, написание оптимального кода для видеочипов совсем не такое простое и эта задача нуждается в длительной ручной работе, но CUDA как раз и раскрывает все возможности и даёт программисту больший контроль над аппаратными возможностями GPU. Важно, что поддержка Nvidia CUDA есть у чипов G8x, G9x и GT2xx, применяемых в видеокартах Geforce серий 8, 9 и 200, которые очень широко распространены. В настоящее время выпущена финальная версия CUDA 2.0, в которой появились некоторые новые возможности, например, поддержка расчётов с двойной точностью. CUDA доступна на 32-битных и 64-битных операционных системах Linux, Windows и MacOS X.
Разница между CPU и GPU в параллельных расчётах
Рост частот универсальных процессоров упёрся в физические ограничения и высокое энергопотребление, и увеличение их производительности всё чаще происходит за счёт размещения нескольких ядер в одном чипе. Продаваемые сейчас процессоры содержат лишь до четырёх ядер (дальнейший рост не будет быстрым) и они предназначены для обычных приложений, используют MIMD множественный поток команд и данных. Каждое ядро работает отдельно от остальных, исполняя разные инструкции для разных процессов.
Специализированные векторные возможности (SSE2 и SSE3) для четырехкомпонентных (одинарная точность вычислений с плавающей точкой) и двухкомпонентных (двойная точность) векторов появились в универсальных процессорах из-за возросших требований графических приложений, в первую очередь. Именно поэтому для определённых задач применение GPU выгоднее, ведь они изначально сделаны для них.
Например, в видеочипах Nvidia основной блок это мультипроцессор с восемью-десятью ядрами и сотнями ALU в целом, несколькими тысячами регистров и небольшим количеством разделяемой общей памяти. Кроме того, видеокарта содержит быструю глобальную память с доступом к ней всех мультипроцессоров, локальную память в каждом мультипроцессоре, а также специальную память для констант.
Самое главное эти несколько ядер мультипроцессора в GPU являются SIMD (одиночный поток команд, множество потоков данных) ядрами. И эти ядра исполняют одни и те же инструкции одновременно, такой стиль программирования является обычным для графических алгоритмов и многих научных задач, но требует специфического программирования. Зато такой подход позволяет увеличить количество исполнительных блоков за счёт их упрощения.
Итак, перечислим основные различия между архитектурами CPU и GPU. Ядра CPU созданы для исполнения одного потока последовательных инструкций с максимальной производительностью, а GPU проектируются для быстрого исполнения большого числа параллельно выполняемых потоков инструкций. Универсальные процессоры оптимизированы для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа и числа с плавающей точкой. При этом доступ к памяти случайный.
Разработчики CPU стараются добиться выполнения как можно большего числа инструкций параллельно, для увеличения производительности. Для этого, начиная с процессоров Intel Pentium, появилось суперскалярное выполнение, обеспечивающее выполнение двух инструкций за такт, а Pentium Pro отличился внеочередным выполнением инструкций. Но у параллельного выполнения последовательного потока инструкций есть определённые базовые ограничения и увеличением количества исполнительных блоков кратного увеличения скорости не добиться.
У видеочипов работа простая и распараллеленная изначально. Видеочип принимает на входе группу полигонов, проводит все необходимые операции, и на выходе выдаёт пиксели. Обработка полигонов и пикселей независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому, из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU. Кроме того, современные GPU также могут исполнять больше одной инструкции за такт (dual issue). Так, архитектура Tesla в некоторых условиях запускает на исполнение операции MAD+MUL или MAD+SFU одновременно.
GPU отличается от CPU ещё и по принципам доступа к памяти. В GPU он связанный и легко предсказуемый - если из памяти читается тексель текстуры, то через некоторое время придёт время и для соседних текселей. Да и при записи то же - пиксель записывается во фреймбуфер, и через несколько тактов будет записываться расположенный рядом с ним. Поэтому организация памяти отличается от той, что используется в CPU. И видеочипу, в отличие от универсальных процессоров, просто не нужна кэш-память большого размера, а для текстур требуются лишь несколько (до 128-256 в нынешних GPU) килобайт.
Да и сама по себе работа с памятью у GPU и CPU несколько отличается. Так, не все центральные процессоры имеют встроенные контроллеры памяти, а у всех GPU обычно есть по несколько контроллеров, вплоть до восьми 64-битных каналов в чипе Nvidia GT200. Кроме того, на видеокартах применяется более быстрая память, и в результате видеочипам доступна в разы большая пропускная способность памяти, что также весьма важно для параллельных расчётов, оперирующих с огромными потоками данных.
В универсальных процессорах большие количества транзисторов и площадь чипа идут на буферы команд, аппаратное предсказание ветвления и огромные объёмы начиповой кэш-памяти. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд. Видеочипы тратят транзисторы на массивы исполнительных блоков, управляющие потоками блоки, разделяемую память небольшого объёма и контроллеры памяти на несколько каналов. Вышеперечисленное не ускоряет выполнение отдельных потоков, оно позволяет чипу обрабатывать нескольких тысяч потоков, одновременно исполняющихся чипом и требующих высокой пропускной способности памяти.
Про отличия в кэшировании. Универсальные центральные процессоры используют кэш-память для увеличения производительности за счёт снижения задержек доступа к памяти, а GPU используют кэш или общую память для увеличения полосы пропускания. CPU снижают задержки доступа к памяти при помощи кэш-памяти большого размера, а также предсказания ветвлений кода. Эти аппаратные части занимают большую часть площади чипа и потребляют много энергии. Видеочипы обходят проблему задержек доступа к памяти при помощи одновременного исполнения тысяч потоков - в то время, когда один из потоков ожидает данных из памяти, видеочип может выполнять вычисления другого потока без ожидания и задержек.
Есть множество различий и в поддержке многопоточности. CPU исполняет 1-2 потока вычислений на одно процессорное ядро, а видеочипы могут поддерживать до 1024 потоков на каждый мультипроцессор, которых в чипе несколько штук. И если переключение с одного потока на другой для CPU стоит сотни тактов, то GPU переключает несколько потоков за один такт.
Кроме того, центральные процессоры используют SIMD (одна инструкция выполняется над многочисленными данными) блоки для векторных вычислений, а видеочипы применяют SIMT (одна инструкция и несколько потоков) для скалярной обработки потоков. SIMT не требует, чтобы разработчик преобразовывал данные в векторы, и допускает произвольные ветвления в потоках.
Вкратце можно сказать, что в отличие от современных универсальных CPU, видеочипы предназначены для параллельных вычислений с большим количеством арифметических операций. И значительно большее число транзисторов GPU работает по прямому назначению - обработке массивов данных, а не управляет исполнением (flow control) немногочисленных последовательных вычислительных потоков. Это схема того, сколько места в CPU и GPU занимает разнообразная логика:

В итоге, основой для эффективного использования мощи GPU в научных и иных неграфических расчётах является распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в видеочипах. К примеру, множество приложений по молекулярному моделированию отлично приспособлено для расчётов на видеочипах, они требуют больших вычислительных мощностей и поэтому удобны для параллельных вычислений. А использование нескольких GPU даёт ещё больше вычислительных мощностей для решения подобных задач.
Выполнение расчётов на GPU показывает отличные результаты в алгоритмах, использующих параллельную обработку данных. То есть, когда одну и ту же последовательность математических операций применяют к большому объёму данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Это предъявляет меньшие требования к управлению исполнением (flow control), а высокая плотность математики и большой объём данных отменяет необходимость в больших кэшах, как на CPU.
В результате всех описанных выше отличий, теоретическая производительность видеочипов значительно превосходит производительность CPU. Компания Nvidia приводит такой график роста производительности CPU и GPU за последние несколько лет:

Естественно, эти данные не без доли лукавства. Ведь на CPU гораздо проще на практике достичь теоретических цифр, да и цифры приведены для одинарной точности в случае GPU, и для двойной в случае CPU. В любом случае, для части параллельных задач одинарной точности хватает, а разница в скорости между универсальными и графическими процессорами весьма велика, и поэтому овчинка стоит выделки.
Первые попытки применения расчётов на GPU
Видеочипы в параллельных математических расчётах пытались использовать довольно давно. Самые первые попытки такого применения были крайне примитивными и ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 году на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) - универсальные вычисления на GPU).
Наиболее известен BrookGPU компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл.br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Естественно, у Brook было множество недостатков, на которых мы останавливались, и о которых ещё подробнее поговорим далее. Но даже просто его появление вызвало значительный прилив внимания тех же Nvidia и ATI к инициативе вычислений на GPU, так как развитие этих возможностей серьёзно изменило рынок в дальнейшем, открыв целый новый его сектор - параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook влились в команду разработчиков Nvidia, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы Nvidia стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала Nvidia CUDA (Compute Unified Device Architecture) новая программно-аппаратная архитектура для параллельных вычислений на Nvidia GPU, которой посвящена эта статья.
Области применения параллельных расчётов на GPU
Чтобы понять, какие преимущества приносит перенос расчётов на видеочипы, приведём усреднённые цифры, полученные исследователями по всему миру. В среднем, при переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным Nvidia):
- Флуоресцентная микроскопия: 12x;
- Молекулярная динамика (non-bonded force calc): 8-16x;
- Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
А это табличка, которую очень любит Nvidia, показывая её на всех презентациях, на которой мы подробнее остановимся во второй части статьи, посвящённой конкретным примерам практических применений CUDA вычислений:

Как видите, цифры весьма привлекательные, особенно впечатляют 100-150-кратные приросты. В следующей статье, посвящённой CUDA, мы подробно разберём некоторые из этих цифр. А сейчас перечислим основные приложения, в которых сейчас применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Подробности о многих применениях можно найти на сайте компании Nvidia в разделе по . Как видите, список довольно большой, но и это ещё не всё! Его можно продолжать, и наверняка можно предположить, что в будущем будут найдены и другие области применения параллельных расчётов на видеочипах, о которых мы пока не догадываемся.
Возможности Nvidia CUDA
Технология CUDA это программно-аппаратная вычислительная архитектура Nvidia, основанная на расширении языка Си, которая даёт возможность организации доступа к набору инструкций графического ускорителя и управления его памятью при организации параллельных вычислений. CUDA помогает реализовывать алгоритмы, выполнимые на графических процессорах видеоускорителей Geforce восьмого поколения и старше (серии Geforce 8, Geforce 9, Geforce 200), а также Quadro и Tesla.
Хотя трудоёмкость программирования GPU при помощи CUDA довольно велика, она ниже, чем с ранними GPGPU решениями. Такие программы требуют разбиения приложения между несколькими мультипроцессорами подобно MPI программированию, но без разделения данных, которые хранятся в общей видеопамяти. И так как CUDA программирование для каждого мультипроцессора подобно OpenMP программированию, оно требует хорошего понимания организации памяти. Но, конечно же, сложность разработки и переноса на CUDA сильно зависит от приложения.
Набор для разработчиков содержит множество примеров кода и хорошо документирован. Процесс обучения потребует около двух-четырёх недель для тех, кто уже знаком с OpenMP и MPI. В основе API лежит расширенный язык Си, а для трансляции кода с этого языка в состав CUDA SDK входит компилятор командной строки nvcc, созданный на основе открытого компилятора Open64.
Перечислим основные характеристики CUDA:
- унифицированное программно-аппаратное решение для параллельных вычислений на видеочипах Nvidia;
- большой набор поддерживаемых решений, от мобильных до мультичиповых
- стандартный язык программирования Си;
- стандартные библиотеки численного анализа FFT (быстрое преобразование Фурье) и BLAS (линейная алгебра);
- оптимизированный обмен данными между CPU и GPU;
- взаимодействие с графическими API OpenGL и DirectX;
- поддержка 32- и 64-битных операционных систем: Windows XP, Windows Vista, Linux и MacOS X;
- возможность разработки на низком уровне.
Касательно поддержки операционных систем нужно добавить, что официально поддерживаются все основные дистрибутивы Linux (Red Hat Enterprise Linux 3.x/4.x/5.x, SUSE Linux 10.x), но, судя по данным энтузиастов, CUDA прекрасно работает и на других сборках: Fedora Core, Ubuntu, Gentoo и др.
Среда разработки CUDA (CUDA Toolkit) включает:
- компилятор nvcc;
- библиотеки FFT и BLAS;
- профилировщик;
- отладчик gdb для GPU;
- CUDA runtime драйвер в комплекте стандартных драйверов Nvidia
- руководство по программированию;
- CUDA Developer SDK (исходный код, утилиты и документация).
В примерах исходного кода: параллельная битонная сортировка (bitonic sort), транспонирование матриц, параллельное префиксное суммирование больших массивов, свёртка изображений, дискретное вейвлет-преобразование, пример взаимодействия с OpenGL и Direct3D, использование библиотек CUBLAS и CUFFT, вычисление цены опциона (формула Блэка-Шоулза, биномиальная модель, метод Монте-Карло), параллельный генератор случайных чисел Mersenne Twister, вычисление гистограммы большого массива, шумоподавление, фильтр Собеля (нахождение границ).
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:

Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании Nvidia отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям:
- интерфейс программирования приложений CUDA основан на стандартном языке программирования Си с расширениями, что упрощает процесс изучения и внедрения архитектуры CUDA;
- CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
- более эффективная передача данных между системной и видеопамятью
- отсутствие необходимости в графических API с избыточностью и накладными расходами;
- линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
- аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
- отсутствие поддержки рекурсии для выполняемых функций;
- минимальная ширина блока в 32 потока;
- закрытая архитектура CUDA, принадлежащая Nvidia.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
Кроме того, CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись - неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
История развития CUDA
Разработка CUDA была анонсирована вместе с чипом G80 в ноябре 2006, а релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. Версия 1.0 вышла в июне 2007 года под запуск в продажу решений Tesla, основанных на чипе G80, и предназначенных для рынка высокопроизводительных вычислений. Затем, в конце года вышла бета-версия CUDA 1.1, которая, несмотря на малозначительное увеличение номера версии, ввела довольно много нового.
Из появившегося в CUDA 1.1 можно отметить включение CUDA-функциональности в обычные видеодрайверы Nvidia. Это означало, что в требованиях к любой CUDA программе достаточно было указать видеокарту серии Geforce 8 и выше, а также минимальную версию драйверов 169.xx. Это очень важно для разработчиков, при соблюдении этих условий CUDA программы будут работать у любого пользователя. Также было добавлено асинхронное выполнение вместе с копированием данных (только для чипов G84, G86, G92 и выше), асинхронная пересылка данных в видеопамять, атомарные операции доступа к памяти, поддержка 64-битных версий Windows и возможность мультичиповой работы CUDA в режиме SLI.
На данный момент актуальной является версия для решений на основе GT200 CUDA 2.0, вышедшая вместе с линейкой Geforce GTX 200. Бета-версия была выпущена ещё весной 2008 года. Во второй версии появились: поддержка вычислений двойной точности (аппаратная поддержка только у GT200), наконец-то поддерживается Windows Vista (32 и 64-битные версии) и Mac OS X, добавлены средства отладки и профилирования, поддерживаются 3D текстуры, оптимизированная пересылка данных.
Что касается вычислений с двойной точностью, то их скорость на текущем аппаратном поколении ниже одинарной точности в несколько раз. Причины рассмотрены в нашей . Реализация в GT200 этой поддержки заключается в том, блоки FP32 не используются для получения результата в четыре раза меньшем темпе, для поддержки FP64 вычислений в Nvidia решили сделать выделенные вычислительные блоки. И в GT200 их в десять раз меньше, чем блоков FP32 (по одному блоку двойной точности на каждый мультипроцессор).
Реально производительность может быть даже ещё меньше, так как архитектура оптимизирована для 32-битного чтения из памяти и регистров, кроме того, двойная точность не нужна в графических приложениях, и в GT200 она сделана скорее, чтобы просто была. Да и современные четырехъядерные процессоры показывают не намного меньшую реальную производительность. Но будучи даже в 10 раз медленнее, чем одинарная точность, такая поддержка полезна для схем со смешанной точностью. Одна из распространенных техник - получить изначально приближенные результаты в одинарной точности, и затем их уточнить в двойной. Теперь это можно сделать прямо на видеокарте, без пересылки промежуточных данных к CPU.
Ещё одна полезная особенность CUDA 2.0 не имеет отношения к GPU, как ни странно. Просто теперь можно компилировать код CUDA в высокоэффективный многопоточный SSE код для быстрого исполнения на центральном процессоре. То есть, теперь эта возможность годится не только для отладки, но и реального использования на системах без видеокарты Nvidia. Ведь использование CUDA в обычном коде сдерживается тем, что видеокарты Nvidia хоть и самые популярные среди выделенных видеорешений, но имеются не во всех системах. И до версии 2.0 в таких случаях пришлось бы делать два разных кода: для CUDA и отдельно для CPU. А теперь можно выполнять любую CUDA программу на CPU с высокой эффективностью, пусть и с меньшей скоростью, чем на видеочипах.
Решения с поддержкой Nvidia CUDA
Все видеокарты, обладающие поддержкой CUDA, могут помочь в ускорении большинства требовательных задач, начиная от аудио- и видеообработки, и заканчивая медициной и научными исследованиями. Единственное реальное ограничение состоит в том, что многие CUDA программы требуют минимум 256 мегабайт видеопамяти, и это одна из важнейших технических характеристик для CUDA-приложений.
Актуальный список поддерживающих CUDA продуктов можно получить на . На момент написания статьи расчёты CUDA поддерживали все продукты серий Geforce 200, Geforce 9 и Geforce 8, в том числе и мобильные продукты, начиная с Geforce 8400M, а также и чипсеты Geforce 8100, 8200 и 8300. Также поддержкой CUDA обладают современные продукты Quadro и все Tesla: S1070, C1060, C870, D870 и S870.


Особо отметим, что вместе с новыми видеокартами Geforce GTX 260 и 280, были анонсированы и соответствующие решения для высокопроизводительных вычислений: Tesla C1060 и S1070 (представленные на фото выше), которые будут доступны для приобретения осенью этого года. GPU в них применён тот же - GT200, в C1060 он один, в S1070 - четыре. Зато, в отличие от игровых решений, в них используется по четыре гигабайта памяти на каждый чип. Из минусов разве что меньшая частота памяти и ПСП, чем у игровых карт, обеспечивающая по 102 гигабайт/с на чип.
Состав Nvidia CUDA
CUDA включает два API: высокого уровня (CUDA Runtime API) и низкого (CUDA Driver API), хотя в одной программе одновременное использование обоих невозможно, нужно использовать или один или другой. Высокоуровневый работает «сверху» низкоуровневого, все вызовы runtime транслируются в простые инструкции, обрабатываемые низкоуровневым Driver API. Но даже «высокоуровневый» API предполагает знания об устройстве и работе видеочипов Nvidia, слишком высокого уровня абстракции там нет.

Есть и ещё один уровень, даже более высокий две библиотеки:
CUBLAS CUDA вариант BLAS (Basic Linear Algebra Subprograms), предназначенный для вычислений задач линейной алгебры и использующий прямой доступ к ресурсам GPU;
CUFFT CUDA вариант библиотеки Fast Fourier Transform для расчёта быстрого преобразования Фурье, широко используемого при обработке сигналов. Поддерживаются следующие типы преобразований: complex-complex (C2C), real-complex (R2C) и complex-real (C2R).
Рассмотрим эти библиотеки подробнее. CUBLAS это переведённые на язык CUDA стандартные алгоритмы линейной алгебры, на данный момент поддерживается только определённый набор основных функций CUBLAS. Библиотеку очень легко использовать: нужно создать матрицу и векторные объекты в памяти видеокарты, заполнить их данными, вызвать требуемые функции CUBLAS, и загрузить результаты из видеопамяти обратно в системную. CUBLAS содержит специальные функции для создания и уничтожения объектов в памяти GPU, а также для чтения и записи данных в эту память. Поддерживаемые функции BLAS: уровни 1, 2 и 3 для действительных чисел, уровень 1 CGEMM для комплексных. Уровень 1 это векторно-векторные операции, уровень 2 векторно-матричные операции, уровень 3 матрично-матричные операции.
CUFFT CUDA вариант функции быстрого преобразования Фурье широко используемой и очень важной при анализе сигналов, фильтрации и т.п. CUFFT предоставляет простой интерфейс для эффективного вычисления FFT на видеочипах производства Nvidia без необходимости в разработке собственного варианта FFT для GPU. CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах , для 1D поддерживается размер до 8 миллионов элементов.
Основы создания программ на CUDA
Для понимания дальнейшего текста следует разбираться в базовых архитектурных особенностях видеочипов Nvidia. GPU состоит из нескольких кластеров текстурных блоков (Texture Processing Cluster). Каждый кластер состоит из укрупнённого блока текстурных выборок и двух-трех потоковых мультипроцессоров, каждый из которых состоит из восьми вычислительных устройств и двух суперфункциональных блоков. Все инструкции выполняются по принципу SIMD, когда одна инструкция применяется ко всем потокам в warp (термин из текстильной промышленности, в CUDA это группа из 32 потоков минимальный объём данных, обрабатываемых мультипроцессорами). Этот способ выполнения назвали SIMT (single instruction multiple threads одна инструкция и много потоков).

Каждый из мультипроцессоров имеет определённые ресурсы. Так, есть специальная разделяемая память объемом 16 килобайт на мультипроцессор. Но это не кэш, так как программист может использовать её для любых нужд, подобно Local Store в SPU процессоров Cell. Эта разделяемая память позволяет обмениваться информацией между потоками одного блока. Важно, что все потоки одного блока всегда выполняются одним и тем же мультипроцессором. А потоки из разных блоков обмениваться данными не могут, и нужно помнить это ограничение. Разделяемая память часто бывает полезной, кроме тех случаев, когда несколько потоков обращаются к одному банку памяти. Мультипроцессоры могут обращаться и к видеопамяти, но с большими задержками и худшей пропускной способностью. Для ускорения доступа и снижения частоты обращения к видеопамяти, у мультипроцессоров есть по 8 килобайт кэша на константы и текстурные данные.
Мультипроцессор использует 8192-16384 (для G8x/G9x и GT2xx, соответственно) регистра, общие для всех потоков всех блоков, выполняемых на нём. Максимальное число блоков на один мультипроцессор для G8x/G9x равно восьми, а число warp 24 (768 потоков на один мультипроцессор). Всего топовые видеокарты серий Geforce 8 и 9 могут обрабатывать до 12288 потоков единовременно. Geforce GTX 280 на основе GT200 предлагает до 1024 потоков на мультипроцессор, в нём есть 10 кластеров по три мультипроцессора, обрабатывающих до 30720 потоков. Знание этих ограничений позволяет оптимизировать алгоритмы под доступные ресурсы.
Первым шагом при переносе существующего приложения на CUDA является его профилирование и определение участков кода, являющихся «бутылочным горлышком», тормозящим работу. Если среди таких участков есть подходящие для быстрого параллельного исполнения, эти функции переносятся на Cи расширения CUDA для выполнения на GPU. Программа компилируется при помощи поставляемого Nvidia компилятора, который генерирует код и для CPU, и для GPU. При исполнении программы, центральный процессор выполняет свои порции кода, а GPU выполняет CUDA код с наиболее тяжелыми параллельными вычислениями. Эта часть, предназначенная для GPU, называется ядром (kernel). В ядре определяются операции, которые будут исполнены над данными.
Видеочип получает ядро и создает копии для каждого элемента данных. Эти копии называются потоками (thread). Поток содержит счётчик, регистры и состояние. Для больших объёмов данных, таких как обработка изображений, запускаются миллионы потоков. Потоки выполняются группами по 32 штуки, называемыми warp"ы. Warp"ам назначается исполнение на определенных потоковых мультипроцессорах. Каждый мультипроцессор состоит из восьми ядер потоковых процессоров, которые выполняют одну инструкцию MAD за один такт. Для исполнения одного 32-поточного warp"а требуется четыре такта работы мультипроцессора (речь о частоте shader domain, которая равна 1.5 ГГц и выше).
Мультипроцессор не является традиционным многоядерным процессором, он отлично приспособлен для многопоточности, поддерживая до 32 warp"ов единовременно. Каждый такт аппаратное обеспечение выбирает, какой из warp"ов исполнять, и переключается от одного к другому без потерь в тактах. Если проводить аналогию с центральным процессором, это похоже на одновременное исполнение 32 программ и переключение между ними каждый такт без потерь на переключение контекста. Реально ядра CPU поддерживают единовременное выполнение одной программы и переключаются на другие с задержкой в сотни тактов.
Модель программирования CUDA
Повторимся, что CUDA использует параллельную модель вычислений, когда каждый из SIMD процессоров выполняет ту же инструкцию над разными элементами данных параллельно. GPU является вычислительным устройством, сопроцессором (device) для центрального процессора (host), обладающим собственной памятью и обрабатывающим параллельно большое количество потоков. Ядром (kernel) называется функция для GPU, исполняемая потоками (аналогия из 3D графики - шейдер).
Мы говорили выше, что видеочип отличается от CPU тем, что может обрабатывать одновременно десятки тысяч потоков, что обычно для графики, которая хорошо распараллеливается. Каждый поток скалярен, не требует упаковки данных в 4-компонентные векторы, что удобнее для большинства задач. Количество логических потоков и блоков потоков превосходит количество физических исполнительных устройств, что даёт хорошую масштабируемость для всего модельного ряда решений компании.
Модель программирования в CUDA предполагает группирование потоков. Потоки объединяются в блоки потоков (thread block) одномерные или двумерные сетки потоков, взаимодействующих между собой при помощи разделяемой памяти и точек синхронизации. Программа (ядро, kernel) исполняется над сеткой (grid) блоков потоков (thread blocks), см. рисунок ниже. Одновременно исполняется одна сетка. Каждый блок может быть одно-, двух- или трехмерным по форме, и может состоять из 512 потоков на текущем аппаратном обеспечении.

Блоки потоков выполняются в виде небольших групп, называемых варп (warp), размер которых 32 потока. Это минимальный объём данных, которые могут обрабатываться в мультипроцессорах. И так как это не всегда удобно, CUDA позволяет работать и с блоками, содержащими от 64 до 512 потоков.
Группировка блоков в сетки позволяет уйти от ограничений и применить ядро к большему числу потоков за один вызов. Это помогает и при масштабировании. Если у GPU недостаточно ресурсов, он будет выполнять блоки последовательно. В обратном случае, блоки могут выполняться параллельно, что важно для оптимального распределения работы на видеочипах разного уровня, начиная от мобильных и интегрированных.
Модель памяти CUDA
Модель памяти в CUDA отличается возможностью побайтной адресации, поддержкой как gather, так и scatter. Доступно довольно большое количество регистров на каждый потоковый процессор, до 1024 штук. Доступ к ним очень быстрый, хранить в них можно 32-битные целые или числа с плавающей точкой.
Каждый поток имеет доступ к следующим типам памяти:

Глобальная память самый большой объём памяти, доступный для всех мультипроцессоров на видеочипе, размер составляет от 256 мегабайт до 1.5 гигабайт на текущих решениях (и до 4 Гбайт на Tesla). Обладает высокой пропускной способностью, более 100 гигабайт/с для топовых решений Nvidia, но очень большими задержками в несколько сот тактов. Не кэшируется, поддерживает обобщённые инструкции load и store, и обычные указатели на память.
Локальная память это небольшой объём памяти, к которому имеет доступ только один потоковый процессор. Она относительно медленная такая же, как и глобальная.
Разделяемая память это 16-килобайтный (в видеочипах нынешней архитектуры) блок памяти с общим доступом для всех потоковых процессоров в мультипроцессоре. Эта память весьма быстрая, такая же, как регистры. Она обеспечивает взаимодействие потоков, управляется разработчиком напрямую и имеет низкие задержки. Преимущества разделяемой памяти: использование в виде управляемого программистом кэша первого уровня, снижение задержек при доступе исполнительных блоков (ALU) к данным, сокращение количества обращений к глобальной памяти.
Память констант - область памяти объемом 64 килобайта (то же - для нынешних GPU), доступная только для чтения всеми мультипроцессорами. Она кэшируется по 8 килобайт на каждый мультипроцессор. Довольно медленная - задержка в несколько сот тактов при отсутствии нужных данных в кэше.
Текстурная память блок памяти, доступный для чтения всеми мультипроцессорами. Выборка данных осуществляется при помощи текстурных блоков видеочипа, поэтому предоставляются возможности линейной интерполяции данных без дополнительных затрат. Кэшируется по 8 килобайт на каждый мультипроцессор. Медленная, как глобальная сотни тактов задержки при отсутствии данных в кэше.
Естественно, что глобальная, локальная, текстурная и память констант - это физически одна и та же память, известная как локальная видеопамять видеокарты. Их отличия в различных алгоритмах кэширования и моделях доступа. Центральный процессор может обновлять и запрашивать только внешнюю память: глобальную, константную и текстурную.

Из написанного выше понятно, что CUDA предполагает специальный подход к разработке, не совсем такой, как принят в программах для CPU. Нужно помнить о разных типах памяти, о том, что локальная и глобальная память не кэшируется и задержки при доступе к ней гораздо выше, чем у регистровой памяти, так как она физически находится в отдельных микросхемах.
Типичный, но не обязательный шаблон решения задач:
- задача разбивается на подзадачи;
- входные данные делятся на блоки, которые вмещаются в разделяемую память;
- каждый блок обрабатывается блоком потоков;
- подблок подгружается в разделяемую память из глобальной;
- над данными в разделяемой памяти проводятся соответствующие вычисления;
- результаты копируются из разделяемой памяти обратно в глобальную.
Среда программирования
В состав CUDA входят runtime библиотеки:
- общая часть, предоставляющая встроенные векторные типы и подмножества вызовов RTL, поддерживаемые на CPU и GPU;
- CPU-компонента, для управления одним или несколькими GPU;
- GPU-компонента, предоставляющая специфические функции для GPU.
Основной процесс приложения CUDA работает на универсальном процессоре (host), он запускает несколько копий процессов kernel на видеокарте. Код для CPU делает следующее: инициализирует GPU, распределяет память на видеокарте и системе, копирует константы в память видеокарты, запускает несколько копий процессов kernel на видеокарте, копирует полученный результат из видеопамяти, освобождает память и завершает работу.
В качестве примера для понимания приведем CPU код для сложения векторов, представленный в CUDA:

Функции, исполняемые видеочипом, имеют следующие ограничения: отсутствует рекурсия, нет статических переменных внутри функций и переменного числа аргументов. Поддерживается два вида управления памятью: линейная память с доступом по 32-битным указателям, и CUDA-массивы с доступом только через функции текстурной выборки.
Программы на CUDA могут взаимодействовать с графическими API: для рендеринга данных, сгенерированных в программе, для считывания результатов рендеринга и их обработки средствами CUDA (например, при реализации фильтров постобработки). Для этого ресурсы графических API могут быть отображены (с получением адреса ресурса) в пространство глобальной памяти CUDA. Поддерживаются следующие типы ресурсов графических API: Buffer Objects (PBO / VBO) в OpenGL, вершинные буферы и текстуры (2D, 3D и кубические карты) Direct3D9.
Стадии компиляции CUDA-приложения:

Файлы исходного кода на CUDA C компилируются при помощи программы NVCC, которая является оболочкой над другими инструментами, и вызывает их: cudacc, g++, cl и др. NVCC генерирует: код для центрального процессора, который компилируется вместе с остальными частями приложения, написанными на чистом Си, и объектный код PTX для видеочипа. Исполнимые файлы с кодом на CUDA в обязательном порядке требуют наличия библиотек CUDA runtime library (cudart) и CUDA core library (cuda).
Оптимизация программ на CUDA
Естественно, в рамках обзорной статьи невозможно рассмотреть серьёзные вопросы оптимизации в CUDA программировании. Поэтому просто вкратце расскажем о базовых вещах. Для эффективного использования возможностей CUDA нужно забыть про обычные методы написания программ для CPU, и использовать те алгоритмы, которые хорошо распараллеливаются на тысячи потоков. Также важно найти оптимальное место для хранения данных (регистры, разделяемая память и т.п.), минимизировать передачу данных между CPU и GPU, использовать буферизацию.
В общих чертах, при оптимизации программы CUDA нужно постараться добиться оптимального баланса между размером и количеством блоков. Большее количество потоков в блоке снизит влияние задержек памяти, но снизит и доступное число регистров. Кроме того, блок из 512 потоков неэффективен, сама Nvidia рекомендует использовать блоки по 128 или 256 потоков, как компромиссное значение для достижения оптимальных задержек и количества регистров.
Среди основных моментов оптимизации программ CUDA: как можно более активное использование разделяемой памяти, так как она значительно быстрее глобальной видеопамяти видеокарты; операции чтения и записи из глобальной памяти должны быть объединены (coalesced) по возможности. Для этого нужно использовать специальные типы данных для чтения и записи сразу по 32/64/128 бита данных одной операцией. Если операции чтения трудно объединить, можно попробовать использовать текстурные выборки.
Выводы
Представленная компанией Nvidia программно-аппаратная архитектура для расчётов на видеочипах CUDA хорошо подходит для решения широкого круга задач с высоким параллелизмом. CUDA работает на большом количестве видеочипов Nvidia, и улучшает модель программирования GPU, значительно упрощая её и добавляя большое количество возможностей, таких как разделяемая память, возможность синхронизации потоков, вычисления с двойной точностью и целочисленные операции.
CUDA это доступная каждому разработчику ПО технология, её может использовать любой программист, знающий язык Си. Придётся только привыкнуть к иной парадигме программирования, присущей параллельным вычислениям. Но если алгоритм в принципе хорошо распараллеливается, то изучение и затраты времени на программирование на CUDA вернутся в многократном размере.
Вполне вероятно, что в силу широкого распространения видеокарт в мире, развитие параллельных вычислений на GPU сильно повлияет на индустрию высокопроизводительных вычислений. Эти возможности уже вызвали большой интерес в научных кругах, да и не только в них. Ведь потенциальные возможности ускорения хорошо поддающихся распараллеливанию алгоритмов (на доступном аппаратном обеспечении, что не менее важно) сразу в десятки раз бывают не так часто.
Универсальные процессоры развиваются довольно медленно, у них нет таких скачков производительности. По сути, пусть это и звучит слишком громко, все нуждающиеся в быстрых вычислителях теперь могут получить недорогой персональный суперкомпьютер на своём столе, иногда даже не вкладывая дополнительных средств, так как видеокарты Nvidia широко распространены. Не говоря уже об увеличении эффективности в терминах GFLOPS/$ и GFLOPS/Вт, которые так нравятся производителям GPU.
Будущее множества вычислений явно за параллельными алгоритмами, почти все новые решения и инициативы направлены в эту сторону. Пока что, впрочем, развитие новых парадигм находится на начальном этапе, приходится вручную создавать потоки и планировать доступ к памяти, что усложняет задачи по сравнению с привычным программированием. Но технология CUDA сделала шаг в правильном направлении и в ней явно проглядывается успешное решение, особенно если Nvidia удастся убедить как можно разработчиков в его пользе и перспективах.
Но, конечно, GPU не заменят CPU. В их нынешнем виде они и не предназначены для этого. Сейчас что видеочипы движутся постепенно в сторону CPU, становясь всё более универсальными (расчёты с плавающей точкой одинарной и двойной точности, целочисленные вычисления), так и CPU становятся всё более «параллельными», обзаводясь большим количеством ядер, технологиями многопоточности, не говоря про появление блоков SIMD и проектов гетерогенных процессоров. Скорее всего, GPU и CPU в будущем просто сольются. Известно, что многие компании, в том числе Intel и AMD работают над подобными проектами. И неважно, будут ли GPU поглощены CPU, или наоборот.
В статье мы в основном говорили о преимуществах CUDA. Но есть и ложечка дёгтя. Один из немногочисленных недостатков CUDA - слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии Geforce 8 и 9 и соответствующих Quadro и Tesla. Да, таких решений в мире очень много, Nvidia приводит цифру в 90 миллионов CUDA-совместимых видеочипов. Это просто отлично, но ведь конкуренты предлагают свои решения, отличные от CUDA. Так, у AMD есть Stream Computing, у Intel в будущем будет Ct.
Которая из технологий победит, станет распространённой и проживёт дольше остальных - покажет только время. Но у CUDA есть неплохие шансы, так как по сравнению с Stream Computing, например, она представляет более развитую и удобную для использования среду программирования на обычном языке Си. Возможно, в определении поможет третья сторона, выпустив некое общее решение. К примеру, в следующем обновлении DirectX под версией 11, компанией Microsoft обещаны вычислительные шейдеры, которые и могут стать неким усреднённым решением, устраивающим всех, или почти всех.
Судя по предварительным данным, этот новый тип шейдеров заимствует многое из модели CUDA. И программируя в этой среде уже сейчас, можно получить преимущества сразу и необходимые навыки для будущего. С точки зрения высокопроизводительных вычислений, у DirectX также есть явный недостаток в виде плохой переносимости, так как этот API ограничен платформой Windows. Впрочем, разрабатывается и ещё один стандарт - открытая мультиплатформенная инициатива OpenCL, которая поддерживается большинством компаний, среди которых Nvidia, AMD, Intel, IBM и многие другие.
Не забывайте, что в следующей статье по CUDA вас ждёт исследование конкретных практических применений научных и других неграфических вычислений, выполненных разработчиками из разных уголков нашей планеты при помощи Nvidia CUDA.
Ядра CUDA – условное обозначение скалярных вычислительных блоков в видео-чипах NVidia , начиная с G 80 (GeForce 8 xxx, Tesla C-D-S870 , FX4 /5600 , 360M ). Сами чипы являются производными архитектуры. К слову, потому компания NVidia так охотно взялась за разработку собственных процессоров Tegra Series , основанных тоже на RISC архитектуре. Опыт работы с данными архитектурами очень большой.
CUDA ядро содержит в себе один один векторный и один скалярный юнит, которые за один такт выполняют по одной векторной и по одной скалярной операции, передавая вычисления другому мультипроцессору, либо в для дальнейшей обработки. Массив из сотен и тысяч таких ядер, представляет из себя значительную вычислительную мощность и может выполнять различные задачи в зависимости от требований, при наличии определённого софта поддерживающего . Применение может быть разнообразным: декодирование видеопотока, ускорение 2D/3D графики, облачные вычисления, специализированные математические анализы и т.д.
Довольно часто, объединённые профессиональные карты NVidia Tesla и NVidia Quadro , являются костяком современных суперкомпьютеров.
CUDA — ядра не претерпели каких либо значимых изменений со времён G 80 , но увеличивается их количество (совместно с другими блоками — ROP , Texture Units & etc) и эффективность параллельных взаимодействий друг с другом (улучшаются модули Giga Thread ).

К примеру:
GeForce
GTX 460 — 336 CUDA ядер
GTX 580 — 512 CUDA ядер
8800GTX — 128 CUDA ядер
От количества потоковых процессоров (CUDA ), практически пропорционально увеличивается производительность в шейдерных вычислениях (при равномерном увеличении количества и других элементов).
Начиная с чипа GK110 (NVidia GeForce GTX 680) — CUDA ядра теперь не имеют удвоенную частоту, а общую со всеми остальными блоками чипа. Вместо этого было увеличено их количество примерно в три раза в сравнении с предыдущим поколением G110 .